
Maschinelle Übersetzung (MÜ) soll es ermöglichen, fremde Sprachen ohne Lernaufwand oder Umweg über Dritte zu verstehen. Dieses Konzept ist ein uralter Menschheitstraum. Man denke zum Beispiel an alte Geschichten wie den Turmbau zu Babel oder neuere Science-Fiction-Elemente wie den Babelfisch.
Geschichte der maschinellen Übersetzung
Die Forschung zur praktischen Umsetzung dieses Traums war zunächst aber vor allem von militärischem Interesse geprägt. Als eines der frühesten Projekte gilt ein Übersetzungsprogramm Russisch-Englisch, das für das US-amerikanische Militär entwickelt wurde.
1966 ließ das Verteidigungsministerium der USA dann den sogenannten APAC-Bericht erstellen, in dem die Machbarkeit maschineller Übersetzung untersucht wurde. Das vernichtende Urteil: maschinelle Übersetzung wurde als grundsätzlich unrealisierbar bewertet. In der Folge kam die entsprechende Forschung über Jahrzehnte nahezu zum Erliegen.
Erst in den 1980er-Jahren nahmen verschiedene Elektrokonzerne (z. B. Siemens) die Forschung erneut auf. Seitdem wurden immer wieder MÜ-Systeme entwickelt, aber keines lieferte wirklich brauchbare Ergebnisse.
Die Funktionsweise der damaligen Systeme bezeichnet man als „regelbasiert“. Dies bedeutet, dass im Programm Informationen zu Wortbildung, Satzstellung und Bedeutungen für die jeweilige Sprache hinterlegt wurden, auf deren Basis die Übersetzung der Texte erfolgte.
Maschinelle Übersetzung im 21. Jahrhundert
In den 2000er-Jahren wurden die regelbasierten Systeme weiterentwickelt und es gab neue Ansätze. In dieser Zeit kam z. B. der Google Übersetzer auf den Markt. Die Funktionsweise war weiterhin regelbasiert und/oder statistisch.
Der statistische Ansatz wird auch als „korpusbasiert“ bezeichnet. Dabei liegt dem Programm eine große Menge (ein sogenanntes Korpus) zweisprachiger Texte zugrunde. Auf deren Basis werden statistische Muster erkannt. Bei der maschinellen Übersetzung bildet die Engine diese Muster nach und übersetzt so Text von der einen in die andere Sprache.
Trotz dieser Weiterentwicklungen blieben die Ergebnisse maschineller Übersetzung bis in die 2010er-Jahre hinein unbefriedigend. Zu diesem Zeitpunkt entwickelte die Forschung eine neue Hypothese: Funktionierende MÜ-Systeme müssen über Kompetenzen verfügen, die über reines Sprachverständnis hinausgehen, z. B. konzeptuelles Wissen, Metawissen, Kenntnisse über die menschliche Umwelt, Konventionen sozialer Interaktion usw.
Aus dem Nähkästchen von Übersetzungsmanagerin Rebecca:

2012 habe ich meine Masterarbeit über die Ergebnisse von Google Übersetzer geschrieben. Ich habe untersucht, wie das Programm einen Auszug aus einer medizinischen Studie und eine Pressemeldung über diese Studie übersetzt. Die Qualität der Übersetzung war nicht brauchbar, insbesondere aus den folgenden Gründen:
- Die Engine arbeitete damals eindeutig satzbasiert und verstand z. B. nicht, was eine Überschrift ist.
- Fachwörter waren völlig uneinheitlich übersetzt. So wurde z. B. das englische Wort score im Textverlauf als „Score“, „Punktzahl“ und „Partitur“ übersetzt. Gemeint war in allen Fällen „Punktzahl“.
- Die Übersetzungen enthielten auffällige grammatikalische Fehler, die zum Beispiel die Grammatikprüfung von Microsoft Word gefunden hätte. Das hat mich am meisten schockiert, da dieser Fehlertyp absolut vermeidbar gewesen wäre durch Nachschalten einer Software zur Grammatikprüfung.
Durch diese gravierenden Mängel war Google Übersetzer zum damaligen Zeitpunkt als maschinelle Übersetzungsengine für den professionellen Gebrauch nicht nutzbar. Für den privaten Gebrauch und um schnell den groben Inhalt eines fremdsprachigen Texts (z. B. einer Website) zu verstehen, war die Engine aber auch damals schon geeignet.
Durchbruch dank künstlicher Intelligenz
Seit 2016 wird die maschinelle Übersetzung unter Einbindung neuronaler Netze, also künstlicher Intelligenz (KI), weiterentwickelt. Die Funktionsweise ist dem statistischen Ansatz sehr ähnlich, denn ein KI-gestütztes Übersetzungsprogramm ist ebenfalls korpusbasiert. Obendrein wird es aber über Machine Learning gezielt trainiert, damit es Zusammenhänge zwischen den Ausgangs- und Zieltexten im Korpus erkennt und diese reproduzieren kann. Das Ergebnis sind präzisere Übersetzungen als bei allen vorherigen Systemen. DeepL ist ein Beispiel für diese neuen, besseren Systeme. Allerdings lässt sich nicht nachvollziehen, wie genau diese guten Ergebnisse zustande gekommen sind.
Aus dem Nähkästchen von Übersetzungsmanagerin Rebecca:
Als DeepL 2017 für den kostenlosen Gebrauch online gestellt wurde, machte diese Neuigkeit in meinem (Übersetzerinnen-lastigen) Freundeskreis schnell die Runde. Damals arbeitete ich in einer kleinen Übersetzungsagentur und ich weiß noch genau, wie einer meiner älteren Kollegen sagte: ‚Jaaaa, das ist doch wieder nur ein Hype. IBM und viele andere versuchen seit Jahrzehnten, eine MÜ-Engine zu entwickeln. Es hieß immer wieder, das sei jetzt der große Durchbruch, und dann waren die Ergebnisse genauso schlecht wie bei den vorherigen Versuchen. Das kannst du getrost vergessen.
‘10 Minuten später testeten wir DeepL an einem Marketingtext, den ich gerade übersetzt hatte, und waren baff: Die Übersetzung hatte eine umwerfende Qualität! Sie war stellenweise vielleicht nicht ganz so gut wie meine Humanübersetzung, aber dafür hatte die Engine eine Arbeit, für die ich eine Stunde gebraucht hatte, in wenigen Sekunden erledigt.An diesem Tag hatte ich zum ersten Mal Sorge, dass diese Technik mich arbeitslos machen würde.
Seit der Einbindung von künstlicher Intelligenz liefern die MÜ-Engines auf dem Markt deutlich bessere Übersetzungsergebnisse. Die Ergebnisse sind sogar so gut, dass ihr Einsatz mittlerweile auch in der Arbeit professioneller Übersetzer*innen gängig ist. Die Technik hat Übersetzer*innen jedoch nicht überflüssig gemacht, sondern in der Übersetzungsbranche haben sich verschiedene Service-Levels herausgebildet:
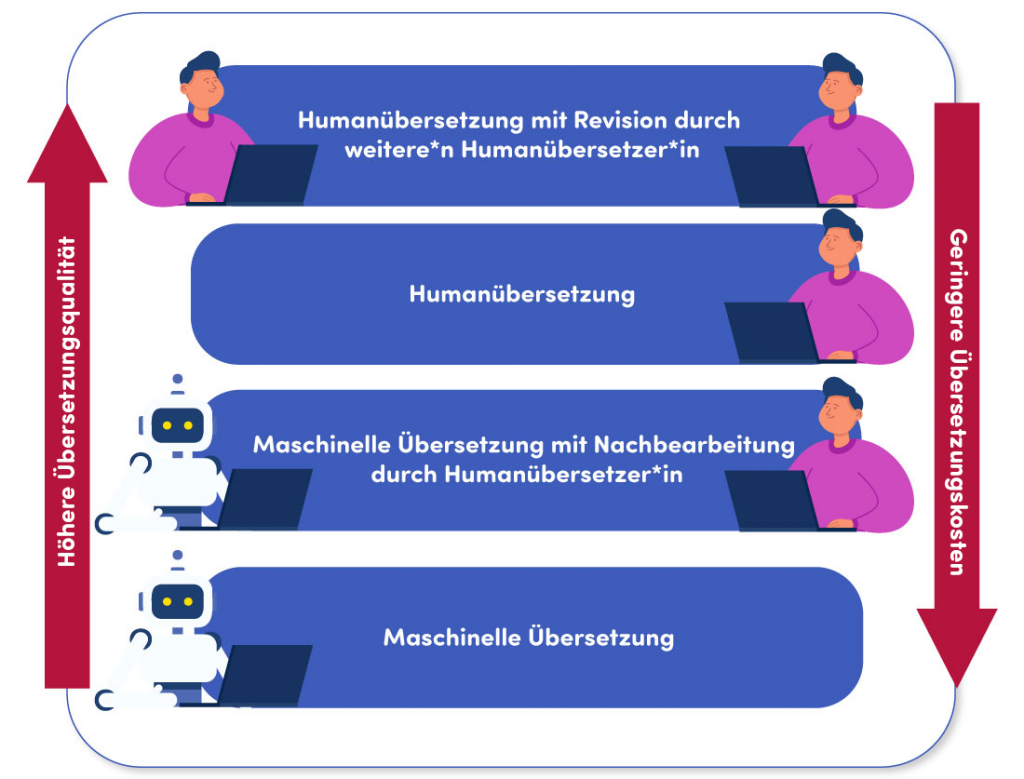
Zu verschiedenen MÜ-Engines gibt es spezielle Plug-ins für die üblichen Arbeitsumgebungen von Übersetzer*innen, sodass auch kundenspezifische Terminologie berücksichtigt werden kann. Auf diese Weise wird die Qualität des Ergebnisses zusätzlich sichergestellt. dictaJet hat sich selbst von den Ergebnissen für technische Texte überzeugt und nutzt die maschinelle Übersetzung mit Nachbearbeitung durch eine*e Humanübersetzer*in mittlerweile erfolgreich für verschiedene Kunden.
Ist KI-gestützte maschinelle Übersetzung zuverlässig?
Maschinelle Übersetzung mit Nachbearbeitung durch eine*n Humanübersetzer*in (kurz MTPE von Englisch Machine Translation with Post-Editing) kommt hierbei immer häufiger zum Einsatz. Post-Editing hat aber seine ganz eigenen Herausforderungen. Denn einerseits liegt diese Tätigkeit nicht allen Übersetzer*innen und andererseits ist es schwieriger, in einem vorübersetzten Text Fehler zu erkennen, als selbst fehlerfrei zu übersetzen. Fatalerweise bezieht sich dies nicht auf banale Tippfehler, sondern vor allem auf inhaltliche Fehler.
Ein weiterer Punkt, der KI-Übersetzungen potenziell unzuverlässig macht, ist die Tatsache, dass niemand genau weiß, wie die Übersetzungsqualität zustande kommt. Dies scheint auf den ersten Blick kein Problem zu sein, denn schließlich überzeugen die Ergebnisse. Wenn die Funktionsweise nicht bekannt ist, kann sie aber auch niemand gezielt steuern. Dadurch könnte es passieren, dass die Qualität irgendwann nicht weiter steigt, sondern plötzlich wieder abnimmt.
Ausblick
Der neueste Stern am KI-Himmel ist ChatGPT. Es ist zwar keine MÜ-Engine, aber sie arbeitet ebenfalls mit Texten und es wäre keine Überraschung, wenn die Technik dahinter sich auch auf die Übersetzungsbranche auswirken würde. So könnten die Menschen sich ihre Texte z. B. direkt in der Zielsprache schreiben lassen, statt erst in ihrer eigenen Sprache zu schreiben und dann übersetzen zu lassen. Sie könnten die inhaltliche Qualität dieser Texte zwar u. U. nicht selbst kontrollieren, die sprachliche Qualität wäre aber weitestgehend sichergestellt. Viele Leute würden dieses Risiko sicher gerne in Kauf nehmen, wenn sie sich damit die Übersetzungskosten sparen könnten. Ob der Übersetzerberuf dadurch überflüssig wird, bleibt abzuwarten. Die aktuellen Möglichkeiten der maschinellen Übersetzung reichen jedenfalls noch nicht aus, um eine hohe Übersetzungsqualität und Fehlerfreiheit bei sensiblen Texten, z. B. im medizinischen oder juristischen Bereich, sicherzustellen.