Definition
Das Wort Semantik stammt vom griechischen Wort für „bezeichnen“, „zum Zeichen gehörig“ ab. In der Linguistik bezeichnet Semantik die Lehre der Bedeutung von Sprache oder, allgemeiner, von Zeichen. Semantik ist ein Teilgebiet der Semiotik, der Bedeutungslehre von Zeichensystemen.
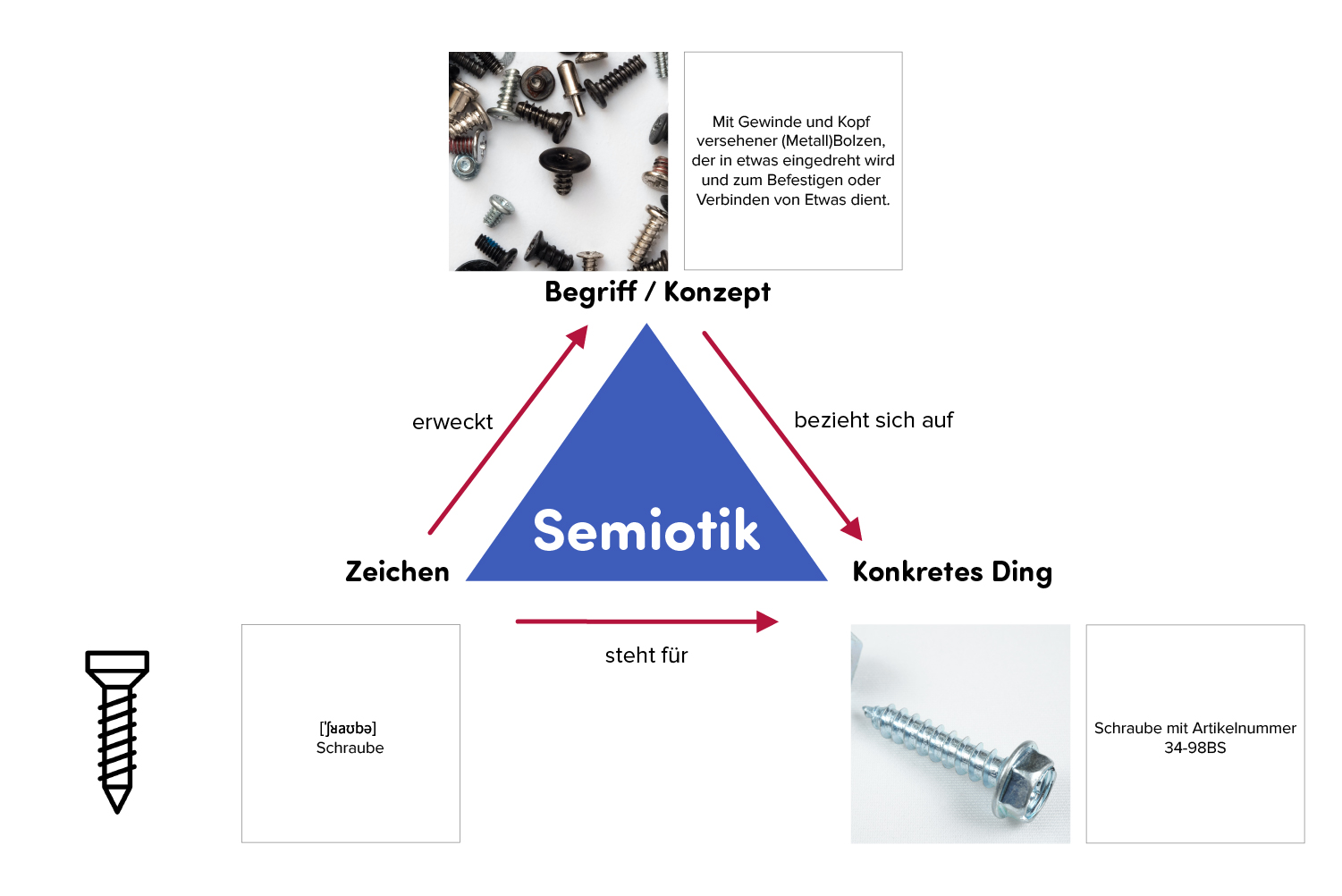
Die Semantik beschäftigt sich also mit dem Inhalt und der Bedeutung von Zeichenketten. Dabei spielt es keine Rolle, ob die Zeichen in schriftlicher, sprachlicher, graphischer oder nonverbaler Form vorliegen. Gesten sind in diesem Sinne also auch Zeichen. In der Informatik steht das Wort „Semantik“ ganz allgemein für die Bedeutung von Informationen.
Semantik bei digitalen Informationssystemen
Digitale Informationssysteme wie Wikipedia, die Google-Suchmaschine oder die Amazon-Plattform arbeiten mit sehr vielen Inhalten. Deren Abfrage funktioniert so gut, weil sie auf einer Technologie basieren, die die Bedeutung der Inhalte erkennt, verwaltet und verarbeitet. Daher bezeichnet man diese Technologie als semantische Technologie.
Mithilfe semantischer Technologie können digitale Informationssysteme ihre eigenen Inhalte (Texte, Abbildungen, Filme, Videos usw.) verstehen und verarbeiten. Dabei imitieren sie die Verarbeitung beim Menschen, die intuitiv passiert und auf erlerntem Wissen und Erfahrungen basiert.
Informationssysteme, die auf semantischen Technologien beruhen, werden auch semantische Anwendungen genannt. Wie mächtig eine semantische Anwendung ist (d. h. wie viele Möglichkeiten sie bietet), hängt davon ab, wie reichhaltig die Semantik ihrer Datengrundlage ist. Die semantische Reichhaltigkeit untergliedert sich in zwei Stufen: Zur ersten Stufe gehören Anwendungen, deren Inhalte mit Bedeutung und Kontext angereichert sind und so ein Wissensnetz bilden. Bei der zweiten Stufe geht es zusätzlich um die Entwicklung einer Ontologie, die über eine sogenannte Inferenzmaschine interpretierbar ist.
Anreicherung von Content mit Bedeutung und Kontext
Im Mittelpunkt der semantischen Technologie steht zunächst die systemtechnische, d. h. maschinenlesbare Anreicherung von Content mit Bedeutung und Kontext. Dies wird wie folgt realisiert:
- Der Content wird anhand vorab festgelegter Metadaten in seiner Beschaffenheit strukturiert, formal beschrieben und dadurch mit maschinenlesbarer Bedeutung angereichert. Die Metadaten werden in einem Wortnetz organisiert. D. h. sie werden in ihrer Bedeutung eindeutig definiert, über Synonyme, Homonyme usw. abgegrenzt und in Ober- und Unterbegriffen hierarchisch organisiert. So können digitale Systeme verstehen, worum es im jeweiligen Inhalt geht.
- Der Content wird über festgelegte und eindeutige (d. h. formale) Aussagen zu anderen Inhalten in Beziehung gesetzt. Diese Vernetzung über aussagenkräftige Beziehungen setzt den Content zusätzlich in einen Kontext.
In der Abbildung wird Content A anhand von Metadaten strukturiert beschrieben, die im gleichfarbigen Rechteck aufgelistet sind. Zusätzlich steht Content A in Beziehung zu weiteren Inhalten innerhalb des Informationssystems. Diese Beziehungen werden anhand von annotierten Richtungspfeilen (z. B. hat_Autor) dargestellt. Der Content zum Autor/zur Autorin wiederum wird ebenfalls anhand von relevanten Metadaten beschrieben.

Vom Wissensnetz zur Ontologie
Durch diese Anreicherung und Verknüpfung wird aus isolierten Inhaltsbausteinen ein Wissensnetz, das automatisch Informationen zu den verschiedensten Abfragen zusammenstellen kann.
Ein solches Wissensnetz kann die Grundlage für die Entwicklung einer Ontologie bilden. Eine Ontologie für eine semantische Anwendung bietet maximalen Bedeutungsreichtum: Zusätzlich zum Wortnetz und den aussagekräftigen Beziehungen wird über Gültigkeitsregeln eine Logik definiert, die das Wissensnetz mit zusätzlicher Semantik anreichert.
Logisches Schlussfolgern mithilfe von Gültigkeitsregeln
Diese Gültigkeitsregeln ermöglichen ein sehr hohes Maß an Semantik und der Einsatz einer sogenannten Inferenzmaschine. Die Inferenzmaschine interpretiert das in der Ontologie repräsentierte Wissen, um logische Schlussfolgerungen zu ziehen. So macht sie neues Wissen sichtbar, das vorher nur implizit vorhanden war.
Dabei gibt es gängige Gültigkeitsregeln, es können aber auch eigene formuliert werden. Ein einfaches Beispiel für eine solche Regel ist die Transitivitätsregel. Sie besagt, dass sich Eigenschaften in einer Klassenhierarchie nach unten vererben. Ein Element hat dann also auch die Eigenschaften der Elemente, die ihm übergeordnet sind.
Mehrwert semantischer Technologien
Anhand der semantischen Technologien versorgen Informationssysteme die Nutzer*innen nicht nur mit passgenauen Informationen zu ihrem Informationsbedarf, sondern liefern auch erweiterte, assoziierte Informationen dazu. Selbst Suchanfragen über unscharfe Begriffe werden vom System verstanden, sobald diese in das Vokabular der Ontologie (Homonyme, Synonyme usw.) aufgenommen wurden.
Das Ziel ist, auch komplexe Fragestellungen beantworten zu können. Dazu werden die über das Wissensnetz vernetzten Elemente gesucht und über die Inferenzmaschine logisch verknüpft. Dank der semantischen Technologie kann das Informationssystem dann z. B. die Anfrage „Zu welchen Themen hat Autor*in D geschrieben?“ beantworten, obwohl zwischen den Inhaltselementen „Autor“ (Content D) und „Thema“ (Content C) keine direkte Verbindung besteht (siehe Abbildung). Die Inferenzmaschine schlussfolgert die Antwort auf die Frage durch die Verbindungen zwischen „Autor“ und „Publikation“ (Content A) sowie zwischen „Publikation“ und „Thema“. Diese Schlussfolgerung basiert ebenfalls auf einer Transitivitätsregel.
Semantische Technologien zeichnen sich also dadurch aus, dass das jeweilige System die Bedeutung der einzelnen Inhaltsbausteine und deren Zusammenhänge interpretieren und somit „verstehen“ kann. Entsprechend werden diese passend zu Kontext und Informationsbedarf der Nutzer*innen automatisch zusammengestellt. Die Bedeutung ist somit der entscheidende Faktor, der die umfassende Funktionsfähigkeit semantischer Anwendungen ermöglicht.